背景和问题
在传统的数据管理系统中,两个命令(对数据的更新)和查询(对数据的请求)都是针对单个数据存储库中的同一组实体执行的。 这些实体可以是关系数据库(如SQL Server)中一个或多个表中的行的子集。
通常在这些系统中,所有创建,读取,更新和删除(CRUD)操作都应用于实体的相同表示形式。 例如,通过数据访问层(DAL)从数据存储器检索表示客户的数据传输对象(DTO)并显示在屏幕上。 用户更新DTO的某些字段(可能通过数据绑定),然后DTO将由DAL保存回数据存储。 同样的DTO用于读写操作。 该图说明了传统的CRUD架构。
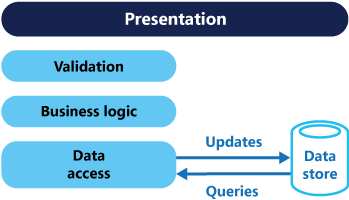
当只有有限的业务逻辑应用于数据操作时,传统的CRUD设计才能正常运行。开发工具提供的支架机制可以非常快速地创建数据访问代码,然后可以根据需要进行自定义。
然而,传统的CRUD方法有一些缺点:
- 这通常意味着数据的读取和写入表示之间存在不匹配的情况,例如即使不需要作为操作的一部分,必须正确更新的附加列或属性。
- 当记录被锁定在协作域中的数据存储中时,数据争用就会发生风险,其中多个角色在同一组数据上并行操作。或者当使用乐观锁定时更新由并发更新引起的冲突。随着系统的复杂性和吞吐量的增加,这些风险将增加。此外,由于数据存储和数据访问层的负载以及检索信息所需的查询的复杂性,传统的方法可能会对性能产生负面影响。
- 它可以使管理安全和权限更加复杂,因为每个实体都受到读写操作的限制,这可能会在错误的上下文中暴露数据。
- 同步的,直接与数据库进行交互在大数据量同时访问的情况下可能会影响性能和响应性,并且可能会产生性能瓶颈。
解决方案CQRS
CQRS介绍
CQRS表示命令查询责任分离。 许多人认为CQRS是整个架构,但它们是错误的。 CQRS只是一个小小的模式。 这种模式首先由Greg Young和Udi Dahan介绍。 他们从Bertrand Meyer在“面向对象软件构建”一书中定义的命令查询分离模式中获得灵感。 CQS背后的主要思想是:“一个方法应该改变一个对象的状态,或者返回一个结果,而不是两者。 换句话说,问问题不应该改变答案。 更正式地,如果方法透明,那么方法应该返回一个值,因此没有副作用。“(维基百科)因此,我们可以将方法分为两组:
- Commands:更改对象或整个系统的状态(有时称为修饰符或变体)。
- Queries:返回结果,不要更改对象的状态。
命令和查询责任分离(CQRS)是一种模式,它通过使用单独的接口来隔离从更新数据(命令)的操作中读取数据(查询)的操作。 这意味着用于查询和更新的数据模型是不同的。 然后,可以隔离模型,如下图所示,尽管这不是绝对要求。

与基于CRUD的系统中使用的单一数据模型相比,在基于CQRS的系统中使用单独的查询和更新模型来简化设计和实现。 然而,一个缺点是与CRUD设计不同,CQRS代码不能使用脚手架机制自动生成。
用于读取数据的查询模型和用于写入数据的更新模型可以访问相同的物理存储,也许通过使用SQL视图或通过快速生成投影。 然而,通常将数据分成不同的物理存储,以最大限度地提高性能,可扩展性和安全性,如下图所示。
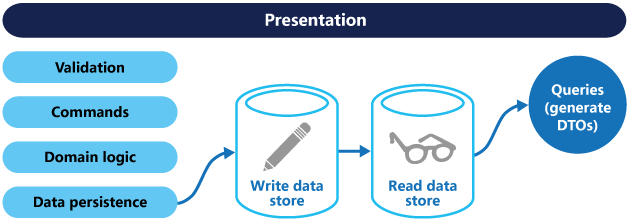
读存储可以是写存储的只读副本,或者读写存储可以具有不同的结构。 使用读取存储器的多个只读副本可以大大提高查询性能和应用程序UI响应性,特别是在只读副本位于靠近应用程序实例的分布式场景中。 某些数据库系统(SQL Server)提供了其他功能,例如故障转移副本,以最大限度地提高可用性。
读写存储器的分离还允许每个存储器被适当地缩放以匹配负载。 例如,读取存储器通常会遇到比写入存储器高得多的负载。
在一个真实的情况下,很简单的告诉哪个是哪个。查询将声明返回类型,命令将返回void。这种模式是广泛适用的,它使得关于对象的推理更容易。另一方面,CQRS仅适用于具体问题。
使用主流方法的许多应用程序都由读写方面常见的模型组成。拥有相同的读写方式可以导致更为复杂的模型,难以维护和优化。
这两种模式的真正实力就是你可以分开改变状态的方法。在处理性能和调优的情况下,这种分离可能非常方便。您可以从写入端分开优化系统的读取端。写方面被称为域。域包含所有行为。阅读方面专门针对报告需求。
这种模式的另一个好处是在大量应用的情况下。您可以将开发人员拆分为在系统不同方面工作的较小团队(读或写),而不了解对方。例如,在阅读方面工作的开发人员不需要了解域模型。
查询端(Query side)
这些查询只会包含获取数据的方法。 从架构的角度来看,这些将是返回客户端在屏幕上显示的DTO的所有方法。 DTO通常是域对象的预测。 在某些情况下,这可能是一个非常痛苦的过程,特别是当需要复杂的DTO时。
使用CQRS可以避免这些预测。 相反,可以引入一种新的投资DTO的方法。 您可以绕过域模型,并使用读取层从数据存储中直接获取DTO。 当应用程序正在请求数据时,可以通过单次调用读取层来完成此操作,该层返回包含所有所需数据的单个DTO。
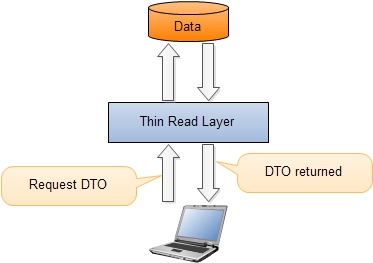
读取层可以直接连接到数据库(数据模型),而使用存储过程来读取数据并不是个好主意。 与数据源的直接连接通过维护和优化使查询变得非常简单。 非正规化数据是有道理的。 这样做的原因是数据通常被查询是执行域行为的多倍。 这种非规范化可能会提高应用程序的性能。
命令端(Command side)
由于读取端已被分离,因此域仅专注于处理命令。 现在域对象不再需要暴露内部状态。 存储库除了GetById之外只有几种查询方法。
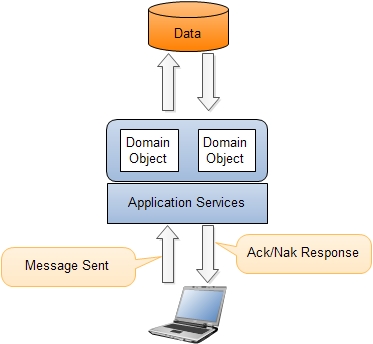
命令由客户端应用程序创建,然后发送到域层。 命令是指示特定实体执行某些操作的消息。 命令命名为DoSomething(例如ChangeName,DeleteOrder …)。 他们指示目标实体做某些可能导致不同结果或失败的事情。 命令由命令处理程序处理。
为什么要使用CQRS?
从CQRS回退一段时间,将域分为DDD中的有界环境的好处之一是使您能够识别并集中于系统更复杂的部分(有界环境),受到不断变化的业务 规则或提供作为关键业务差异化的功能。
只有在提供可识别的业务收益的情况下,才应考虑将CQRS模式应用于特定有限的上下文,而不是因为它是您考虑的默认模式。
您可以通过应用CQRS模式获得的最常见的业务优势是增强的可扩展性,简化您的域的复杂方面,提高解决方案的灵活性,以及更好地适应不断变化的业务需求。
可扩展性
在许多企业系统中,读取次数大大超过了写入次数,因此您的可扩展性要求在每一方面都会有所不同。通过将读取端和写入端分隔为有界环境中的单独模型,您现在可以独立地对每个模型进行扩展。例如,如果您在Microsoft Azure中托管应用程序,则可以为每一方使用不同的角色,然后通过向每个角色添加不同数量的角色实例来独立扩展它们。
可扩展性不应该是您在特定有限上下文中选择实施CQRS模式的唯一原因:
“在非协作域中,您可以在其中添加更多的数据库服务器来支持更多用户,请求和数据,同时添加Web服务器,但没有真正的可伸缩性问题(直到您的大小为Amazon,Google或Facebook)。如果您使用MySQL,SQL Server Express或其他数据库服务器,数据库服务器可以便宜。
降低复杂性
在您的领域的复杂领域,设计和实现负责读取和写入数据的对象可能会加剧复杂性。在许多情况下,复杂的业务逻辑仅在系统处理更新和事务操作时应用;相比之下,读逻辑往往要简单得多。当业务逻辑和读逻辑在同一模型中混合在一起时,处理诸如多用户,共享数据,性能,事务,一致性和过时数据等困难问题变得更加困难。将读取的逻辑和业务逻辑分成单独的模型可以更容易地分离和解决这些复杂的问题。然而,在许多情况下,可能需要一些努力来解开和了解域中现有的模型。
分离问题是Bertrand Meyer的命令查询分离原则背后的关键动机:
“这个原则中真正有价值的想法是,如果您能够清楚地将状态与不改变状态的方法分开,这是非常有用的,这是因为您可以在许多情况下使用查询更有信心,在任何地方介绍它们,你必须更加小心修饰符。“
-Martin Fowler,CommandQuerySeparation
像许多模式一样,您可以将CQRS模式视为将您领域中固有的一些复杂性转化为众所周知的知识,并为解决某些类别问题提供了一种标准方法。
通过分离读取逻辑和业务逻辑来简化有界环境的另一个潜在好处是它可以使测试更容易。
灵活性
使用CQRS模式的解决方案的灵活性主要来自于分离到读取端和写入端模型。在读取方面进行更改变得更加容易,例如在您可以确信不会对业务逻辑的行为产生任何影响的情况下添加新的查询来支持UI中的新的报告屏幕。在写作方面,拥有一个仅关心域内核心业务逻辑的模型意味着您拥有一个比包含读取逻辑的模型更简单的模型来处理。
从长远来看,一个准确描述您的核心域业务逻辑的良好有用的模型将成为宝贵的资产。面对不断变化的商业环境和对您的组织的竞争压力,这将使您更加敏捷。
这种灵活性和敏捷性与DDD中持续集成的概念有关:
“持续整合意味着在上下文中的所有工作正在被合并并且变得足够一致,当分裂发生时,它们被快速地捕获和纠正。
在某些情况下,可能有不同的开发团队在写作方面和阅读方面工作,但实际上这可能取决于特定有界上下文的大小。
专注于业务
如果您使用像CRUD这样的方法,那么该技术往往会塑造解决方案。 采用CQRS模式有助于您专注于业务和构建面向任务的UI。 将不同问题分解为读取端和写入端的结果是在面对不断变化的业务需求时更适应的解决方案。 这导致较长的开发和维护成本较低。
有利于构建基于任务的用户界面
当您实现CQRS模式时,您可以使用命令(通常来自UI)来启动域中的操作。 这些命令通常与域操作和无处不在的语言密切相关。 例如,“为X会议预订两个座位” 您可以设计UI以将这些命令发送到域,而不是启动CRUD风格的操作。 这使得更容易设计直观的基于任务的UI。
什么时候可以考虑CQRS
CQRS模式有一些优点:
- 分工明确,可以负责不同的部分
- 将业务上的命令和查询的职责分离能够提高系统的性能、可扩展性和安全性。并且在系统的演化中能够保持高度的灵活性,能够防止出现CRUD模式中,对查询或者修改中的某一方进行改动,导致另一方出现问题的情况。
- 逻辑清晰,能够看到系统中的那些行为或者操作导致了系统的状态变化。
- 可以从数据驱动(Data-Driven) 转到任务驱动(Task-Driven)以及事件驱动(Event-Driven).
在下场景中,可以考虑使用CQRS模式:
- 当在业务逻辑层有很多操作需要相同的实体或者对象进行操作的时候。CQRS使得我们可以对读和写定义不同的实体和方法,从而可以减少或者避免对某一方面的更改造成冲突
- 对于一些基于任务的用户交互系统,通常这类系统会引导用户通过一系列复杂的步骤和操作,通常会需要一些复杂的领域模型,并且整个团队已经熟悉领域驱动设计技术。写模型有很多和业务逻辑相关的命令操作的堆,输入验证,业务逻辑验证来保证数据的一致性。读模型没有业务逻辑以及验证堆,仅仅是返回DTO对象为视图模型提供数据。读模型最终和写模型相一致。
- 适用于一些需要对查询性能和写入性能分开进行优化的系统,尤其是读/写比非常高的系统,横向扩展是必须的。比如,在很多系统中读操作的请求时远大于写操作。为适应这种场景,可以考虑将写模型抽离出来单独扩展,而将写模型运行在一个或者少数几个实例上。少量的写模型实例能够减少合并冲突发生的情况
- 适用于一些团队中,一些有经验的开发者可以关注复杂的领域模型,这些用到写操作,而另一些经验较少的开发者可以关注用户界面上的读模型。
- 对于系统在将来会随着时间不段演化,有可能会包含不同版本的模型,或者业务规则经常变化的系统
需要和其他系统整合,特别是需要和事件溯源Event Sourcing进行整合的系统,这样子系统的临时异常不会影响整个系统的其他部分。
但是在以下场景中,可能不适宜使用CQRS:
领域模型或者业务逻辑比较简单,这种情况下使用CQRS会把系统搞复杂。
- 对于简单的,CRUD模式的用户界面以及与之相关的数据访问操作已经足够的话,没必要使用CQRS,这些都是一个简单的对数据进行增删改查。
- 不适合在整个系统中到处使用该模式。在整个数据管理场景中的特定模块中CQRS可能比较有用。但是在有些地方使用CQRS会增加系统不必要的复杂性。
CQRS的简单实现
CQRS模式在思想上比较简单,但是实现上还是有些复杂。它涉及到DDD,以及Event Sourcing,这里使用codeproject上的 Introduction to CQRS 这篇文章的例子来说明CQRS模式。这个例子是一个简单的在线记日志(Diary)系统,实现了日志的增删改查功能。整体结构如下:
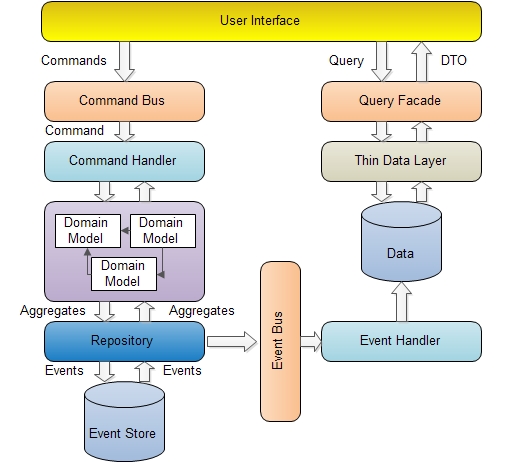
上图很清晰的说明了CQRS在读写方面的分离,在读方面,通过QueryFacade到数据库里去读取数据,这个库有可能是ReportingDB。在写方面,比较复杂,操作通过Command发送到CommandBus上,然后特定的CommandHandler处理请求,产生对应的Event,将Eevnt持久化后,通过EventBus特定的EevntHandler对数据库进行修改等操作。
例子代码可以到codeproject上下载,整体结构如下:

由三个项目构成,Diary.CQRS包含了所有的Domain和消息对象。Configuration通过使用一个名为StructMap的IOC来初始化一些变量方便Web调用,Web是一个简单的MVC3项目,在Controller中有与CQRS交互的代码。
下面分别看Query和Command方面的实现:
Query端的实现
查询方面很简单,日志列表和明细获取就是简单的查询。下面先看列表查询部分的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
| public ActionResult Index() { ViewBag.Model = ServiceLocator.ReportDatabase.GetItems(); return View(); } public ActionResult Edit(Guid id) { var item = ServiceLocator.ReportDatabase.GetById(id); var model = new DiaryItemDto() { Description = item.Description, From = item.From, Id = item.Id, Title = item.Title, To = item.To, Version = item.Version }; return View(model); }
|
ReportDatabase的GetItems和GetById(id)方法就是简单的查询,从命名可以看出他是ReportDatabase。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
| public class ReportDatabase : IReportDatabase { static List<DiaryItemDto> items = new List<DiaryItemDto>(); public DiaryItemDto GetById(Guid id) { return items.Where(a => a.Id == id).FirstOrDefault(); } public void Add(DiaryItemDto item) { items.Add(item); } public void Delete(Guid id) { items.RemoveAll(i => i.Id == id); } public List<DiaryItemDto> GetItems() { return items; } }
|
ReportDataBase只是在内部维护了一个List的DiaryItemDto列表。在使用的时候,是通过IRepositoryDatabase对其进行操作的,这样便于mock代码。
Query端的代码很简单。在实际的应用中,这一块就是直接对DB进行查询,然后通过DTO对象返回,这个DB可能是应对特定场景的报表数据库,这样可以提升查询性能。
下面来看Command端的实现:
Command端实现
Command的实现比较复杂,下面以简单的创建一个新的日志来说明。
在MVC的Control中,可以看到Add的Controller中只调用了一句话:
1 2 3 4 5 6 7
| [HttpPost] public ActionResult Add(DiaryItemDto item) { ServiceLocator.CommandBus.Send(new CreateItemCommand(Guid.NewGuid(), item.Title, item.Description, -1, item.From, item.To)); return RedirectToAction("Index"); }
|
首先声明了一个CreateItemCommand,这个Command只是保存了一些必要的信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| public class CreateItemCommand:Command { public string Title { get; internal set; } public string Description { get;internal set; } public DateTime From { get; internal set; } public DateTime To { get; internal set; } public CreateItemCommand(Guid aggregateId, string title, string description,int version,DateTime from, DateTime to) : base(aggregateId,version) { Title = title; Description = description; From = from; To = to; } }
|
然后将Command发送到了CommandBus上,其实就是让CommandBus来选择合适的CommandHandler来处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| public class CommandBus:ICommandBus { private readonly ICommandHandlerFactory _commandHandlerFactory; public CommandBus(ICommandHandlerFactory commandHandlerFactory) { _commandHandlerFactory = commandHandlerFactory; } public void Send<T>(T command) where T : Command { var handler = _commandHandlerFactory.GetHandler<T>(); if (handler != null) { handler.Execute(command); } else { throw new UnregisteredDomainCommandException("no handler registered"); } } }
|
这个里面需要值得注意的是CommandHandlerFactory这个类型的GetHandler方法,他接受一个类型为T的泛型,这里就是我们之前传入的CreateItemCommand。来看他的GetHandler方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
| public class StructureMapCommandHandlerFactory : ICommandHandlerFactory { public ICommandHandler<T> GetHandler<T>() where T : Command { var handlers = GetHandlerTypes<T>().ToList(); var cmdHandler = handlers.Select(handler => (ICommandHandler<T>)ObjectFactory.GetInstance(handler)).FirstOrDefault(); return cmdHandler; } private IEnumerable<Type> GetHandlerTypes<T>() where T : Command { var handlers = typeof(ICommandHandler<>).Assembly.GetExportedTypes() .Where(x => x.GetInterfaces() .Any(a => a.IsGenericType && a.GetGenericTypeDefinition() == typeof(ICommandHandler<>) )) .Where(h=>h.GetInterfaces() .Any(ii=>ii.GetGenericArguments() .Any(aa=>aa==typeof(T)))).ToList(); return handlers; } }
|
这里可以看到,他首先查找当前的程序集中(ICommandHandler)所在的程序集中的所有的实现了ICommandHandler的接口的类型,然后在所有的类型找查找实现了该泛型接口并且泛型的类型参数类型为T类型的所有类型。以上面的代码为例,就是要找出实现了ICommandHandler接口的类型。可以看到就是CreateItemCommandHandler类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
| public class CreateItemCommandHandler : ICommandHandler<CreateItemCommand> { private IRepository<DiaryItem> _repository; public CreateItemCommandHandler(IRepository<DiaryItem> repository) { _repository = repository; } public void Execute(CreateItemCommand command) { if (command == null) { throw new ArgumentNullException("command"); } if (_repository == null) { throw new InvalidOperationException("Repository is not initialized."); } var aggregate = new DiaryItem(command.Id, command.Title, command.Description, command.From, command.To); aggregate.Version = -1; _repository.Save(aggregate, aggregate.Version); } }
|
找到之后然后使用IOC实例化了该对象返回。
现在CommandBus中,找到了处理特定Command的Handler。然后执行该类型的Execute方法。
可以看到在该类型中实例化了一个名为aggregate的DiaryItem对象。这个和我们之前查询所用到的DiaryItemDto有所不同,这个一个领域对象,里面包含了一系列事件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44
| public class DiaryItem : AggregateRoot, IHandle<ItemCreatedEvent>, IHandle<ItemRenamedEvent>, IHandle<ItemFromChangedEvent>, IHandle<ItemToChangedEvent>, IHandle<ItemDescriptionChangedEvent>, IOriginator { public string Title { get; set; } public DateTime From { get; set; } public DateTime To { get; set; } public string Description { get; set; } public DiaryItem() { } public DiaryItem(Guid id,string title, string description, DateTime from, DateTime to) { ApplyChange(new ItemCreatedEvent(id, title,description, from, to)); } public void ChangeTitle(string title) { ApplyChange(new ItemRenamedEvent(Id, title)); } public void Handle(ItemCreatedEvent e) { Title = e.Title; From = e.From; To = e.To; Id = e.AggregateId; Description = e.Description; Version = e.Version; } public void Handle(ItemRenamedEvent e) { Title = e.Title; } ... }
|
ItemCreatedEvent 事件的定义如下,其实就是用来存储传输过程中需要用到的数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| public class ItemCreatedEvent:Event { public string Title { get; internal set; } public DateTime From { get; internal set; } public DateTime To { get; internal set; } public string Description { get;internal set; } public ItemCreatedEvent(Guid aggregateId, string title , string description, DateTime from, DateTime to) { AggregateId = aggregateId; Title = title; From = from; To = to; Description = description; } }
|
可以看到在Domain对象中,除了定义基本的字段外,还定义了一些相应的事件,比如在构造函数中,实际上是发起了一个名为ItemCreateEvent的事件,同时还定义了处理时间的逻辑,这些逻辑都放在名为Handle的接口方法发,例如ItemCerateEvent的处理方法为Handle(ItemCreateEvent)方法。
ApplyChange方法在AggregateRoot对象中,他是聚集根,这是DDD中的概念。通过这个根可以串起所有对象。 该类实现了IEventProvider接口,他保存了所有在_changes中的所有没有提交的变更,其中的ApplyChange的用来为特定的Event查找Eventhandler的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46
| public abstract class AggregateRoot : IEventProvider { private readonly List<Event> _changes; public Guid Id { get; internal set; } public int Version { get; internal set; } public int EventVersion { get; protected set; } protected AggregateRoot() { _changes = new List<Event>(); } public IEnumerable<Event> GetUncommittedChanges() { return _changes; } public void MarkChangesAsCommitted() { _changes.Clear(); } public void LoadsFromHistory(IEnumerable<Event> history) { foreach (var e in history) ApplyChange(e, false); Version = history.Last().Version; EventVersion = Version; } protected void ApplyChange(Event @event) { ApplyChange(@event, true); } private void ApplyChange(Event @event, bool isNew) { dynamic d = this; d.Handle(Converter.ChangeTo(@event, @event.GetType())); if (isNew) { _changes.Add(@event); } } }
|
在ApplyChange的实现中,this其实就是对应的实现了AggregateRoot的DiaryItem的Domain对象,调用的Handle方法就是我们之前在DiaryItem中定义的行为。然后将该event保存在内部的未提交的事件列表中。相关的信息及事件都保存在了定义的aggregate对象中并返回。
然后Command继续执行,然后调用了_repository.Save(aggregate, aggregate.Version);这个方法。先看这个Repository对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
| public class Repository<T> : IRepository<T> where T : AggregateRoot, new() { private readonly IEventStorage _storage; private static object _lockStorage = new object(); public Repository(IEventStorage storage) { _storage = storage; } public void Save(AggregateRoot aggregate, int expectedVersion) { if (aggregate.GetUncommittedChanges().Any()) { lock (_lockStorage) { var item = new T(); if (expectedVersion != -1) { item = GetById(aggregate.Id); if (item.Version != expectedVersion) { throw new ConcurrencyException(string.Format("Aggregate {0} has been previously modified", item.Id)); } } _storage.Save(aggregate); } } } public T GetById(Guid id) { IEnumerable<Event> events; var memento = _storage.GetMemento<BaseMemento>(id); if (memento != null) { events = _storage.GetEvents(id).Where(e=>e.Version>=memento.Version); } else { events = _storage.GetEvents(id); } var obj = new T(); if(memento!=null) ((IOriginator)obj).SetMemento(memento); obj.LoadsFromHistory(events); return obj; } }
|
这个方法主要是用来对事件进行持久化的。 所有的聚合的变动都会存在该Repository中,首先,检查当前的聚合是否和之前存储在storage中的聚合一致,如果不一致,则表示对象在其他地方被更改过,抛出ConcurrencyException,否则将该变动保存在Event Storage中。
IEventStorage用来存储所有的事件,其实现类型为InMemoryEventStorage。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64
| public class InMemoryEventStorage:IEventStorage { private List<Event> _events; private List<BaseMemento> _mementos; private readonly IEventBus _eventBus; public InMemoryEventStorage(IEventBus eventBus) { _events = new List<Event>(); _mementos = new List<BaseMemento>(); _eventBus = eventBus; } public IEnumerable<Event> GetEvents(Guid aggregateId) { var events = _events.Where(p => p.AggregateId == aggregateId).Select(p => p); if (events.Count() == 0) { throw new AggregateNotFoundException(string.Format("Aggregate with Id: {0} was not found", aggregateId)); } return events; } public void Save(AggregateRoot aggregate) { var uncommittedChanges = aggregate.GetUncommittedChanges(); var version = aggregate.Version; foreach (var @event in uncommittedChanges) { version++; if (version > 2) { if (version % 3 == 0) { var originator = (IOriginator)aggregate; var memento = originator.GetMemento(); memento.Version = version; SaveMemento(memento); } } @event.Version=version; _events.Add(@event); } foreach (var @event in uncommittedChanges) { var desEvent = Converter.ChangeTo(@event, @event.GetType()); _eventBus.Publish(desEvent); } } public T GetMemento<T>(Guid aggregateId) where T : BaseMemento { var memento = _mementos.Where(m => m.Id == aggregateId).Select(m=>m).LastOrDefault(); if (memento != null) return (T) memento; return null; } public void SaveMemento(BaseMemento memento) { _mementos.Add(memento); } }
|
在GetEvent方法中,会找到所有的聚合根Id相关的事件。在Save方法中,将所有的事件保存在内存中,然后每隔三个事件建立一个快照。可以看到这里面使用了备忘录模式。
然后在foreach循环中,对于所有的没有提交的变更,EventBus将该事件发布出去。
现在,所有的发生变更的事件已经记录下来了。事件已经被发布到EventBus上,然后对应的EventHandler再处理对应的事件,然后与DB交互。现在来看EventBus的Publish方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| public class EventBus:IEventBus { private IEventHandlerFactory _eventHandlerFactory; public EventBus(IEventHandlerFactory eventHandlerFactory) { _eventHandlerFactory = eventHandlerFactory; } public void Publish<T>(T @event) where T : Event { var handlers = _eventHandlerFactory.GetHandlers<T>(); foreach (var eventHandler in handlers) { eventHandler.Handle(@event); } } }
|
可以看到EventBus的Publish和CommandBus中的Send方法很相似,都是首先通过EventHandlerFactory查找对应Event的Handler,然后调用其Handler方法。比如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
| public class StructureMapEventHandlerFactory : IEventHandlerFactory { public IEnumerable<IEventHandler<T>> GetHandlers<T>() where T : Event { var handlers = GetHandlerType<T>(); var lstHandlers = handlers.Select(handler => (IEventHandler<T>) ObjectFactory.GetInstance(handler)).ToList(); return lstHandlers; } private static IEnumerable<Type> GetHandlerType<T>() where T : Event { var handlers = typeof(IEventHandler<>).Assembly.GetExportedTypes() .Where(x => x.GetInterfaces() .Any(a => a.IsGenericType && a.GetGenericTypeDefinition() == typeof(IEventHandler<>))) .Where(h => h.GetInterfaces() .Any(ii => ii.GetGenericArguments() .Any(aa => aa == typeof(T)))) .ToList(); return handlers; } }
|
然后返回并实例化了ItemCreatedEventHandler 对象,该对象的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| public class ItemCreatedEventHandler : IEventHandler<ItemCreatedEvent> { private readonly IReportDatabase _reportDatabase; public ItemCreatedEventHandler(IReportDatabase reportDatabase) { _reportDatabase = reportDatabase; } public void Handle(ItemCreatedEvent handle) { DiaryItemDto item = new DiaryItemDto() { Id = handle.AggregateId, Description = handle.Description, From = handle.From, Title = handle.Title, To=handle.To, Version = handle.Version }; _reportDatabase.Add(item); } }
|
可以看到在Handler方法中,从事件中获取参数,然后新建DTO对象,然后将该对象更新到DB中。
到此,整个Command执行完成。
总结
CQRS是一种思想很简单清晰的设计模式,他通过在业务上分离操作和查询来使得系统具有更好的可扩展性及性能,使得能够对系统的不同部分进行扩展和优化。在CQRS中,所有的涉及到对DB的操作都是通过发送Command,然后特定的Command触发对应事件来完成操作,这个过程是异步的,并且所有涉及到对系统的变更行为都包含在具体的事件中,结合Eventing Source模式,可以记录下所有的事件,而不是以往的某一点的数据信息,这些信息可以作为系统的操作日志,可以来对系统进行回退或者重放。
参考文章:
Introduction to CQRS。
浅谈命令查询职责分离(CQRS)模式。

